
O Twitter e o Facebook são fontes de informação constantes e profundas sobre os hábitos do consumidor. Há anos que os profissionais de marketing exploram estes dados utilizando software aplicado a estas plataformas sociais de modo a extrair conversas sobre marcas ou assuntos gerais, como eleições, eventos esportivos ou programas de TV. O processo habitualmente passa por descobrir termos de busca que trazem posts relevantes sobre o(s) tópico(s) pelo qual estamos interessados. Não é muito diferente daquilo que fazemos diariamente no Google: para responder a uma pergunta, basta inserir um termo ou uma frase e procurar nos arquivos labirínticos do buscador.
Os dados capturados por este tipo de software, aos quais geralmente se dá o nome de ferramenta de monitoramento de redes sociais (social media monitoring tool), são depois filtrados, fatiados, picados e ainda analisados pelos analistas de mercado que os transformarão em relatórios inteligentes para os profissionais de Marketing e gestores Hoje em dia, a maior parte destes relatórios estão focados numa só questão: o que as pessoas dizem sobre a minha marca?
Este artigo destina-se aos profissionais de marketing interessados em complementar esse processo, colocando uma questão inteiramente nova: quem são os consumidores influentes da minha marca? Ao mudar a pergunta de o quê para quem pretendemos acrescentar à tradicional abordagem de monitoramento das redes sociais uma dimensão inteiramente nova, focada no consumidor.
Figura 1- Monitoramento das redes sociais: a passagem da análise uni-dimensional para a análise bi-dimensional.
Introdução ao Deep Profile
Vamos falar sobre a principal questão proposta acima. Quando perguntamos quem são os consumidores relevantes para uma marca específica, queremos conhecer esses indivíduos ao nível mais profundo possível. Observando cada post e cada tweet compartilhados publicamente, o nosso objetivo é produzir de forma continua um perfil profundo (deep profile) de cada pessoa. Em condições ideais se espera que o deep profile de cada usuário evolua cada vez que seja capturado um novo item por ele emitido. Além disto, iremos atribuir, na medida do possível, um novo significado à informação pública disponível sobre este consumidor, que até então existia apenas de modo desestruturado e solto.
Veja este exemplo fictício do Twitter:

Figura 2 – Dois tweets fictícios de um usuário do Twitter.
O que é que nos dizem estes dois tweets? O primeiro nos diz que ela transporta insulina e o segundo que ela quer visitar a Grécia. O que queremos fazer em relação a todos os tweets relevantes deste usuário é armazená-los num deep profile, de modo que poderão ser vistos novamente mais tarde. Assim, para este caso, teríamos: @MarJules79 mencionou #Insulina e #Mikonos. Isto pode ser implementado de forma simples através de uma lista de termos relacionados ao âmbito do tema em foco, que é inserida no nosso software.
Vamos olhar para mais dois campos reveladores do Twitter. Primeiro, o campo Bio da @MarJules79 onde ela se descreve:

Figura 3 – A descrição fictícia de @MarJules79 no campo Bio no Twitter.
Do campo Bio podemos ainda agregar ao deep profile: #NewYorker, #trashTV, #trashMovies, #scifi, #art, #dancing, #singing, #Disney, #married, #son.
Finalmente, no campo Localização do Twitter ela escreve: Londres, UK. O seu deep profile tem agora mais um novo item. É importante voltar a observar como o processo de geração de um deep profile não é estático: cada novo tweet da @MarJules79 irá fazê-lo evoluir.
Como acrescentar timelines do Twitter e fazer a análise do deep profile
Uma vez aprendido o conceito de deep profile, estamos prontos para manipular os dados. De agora em diante iremos usar screenshots do Buzzmonitor, a nossa plataforma de Business Intelligence para monitoramento de redes sociais centrada no consumidor.
Como foi mostrado na seção anterior, o deep profile é o principal bloco de construção na geração de insights sobre os consumidores e, como tal, no processo de descoberta de quem é o nosso consumidor. Para a produção de deep profile, em vez de monitorarmos menções a determinada marca, iremos armazenar toda a timeline de um grupo de consumidores. É muito importante percebermos esta distinção porque durante anos fomos condicionados para monitorarmos menções a marcas; agora trata-se de algo fundamentalmente novo: iremos olhar, pela primeira vez, para as timelines inteiras dos consumidores. Na prática isto significa que os nossos projetos de monitoramento de redes sociais com o Buzzmonitor irão armazenar todos os tweets de um grupo de usuários e não apenas os tweets mencionando uma determinada lista de palavras.
Um projeto de monitoramento centrado no consumidor é dividido em duas fases principais:
Primeiro: estabeleça critérios iniciais para a seleção de um grupo de usuários do Twitter, tais como mães de Nova York, adolescentes de Sydney, amantes de vinho da Europa, etc. Na nossa discussão prévia sobre deep profile, mostramos como mergulhar nas timelines dos consumidores de modo a identificar todo e qualquer pedaço de informação sobre a pessoa. Por exemplo, se o seu alvo são adolescentes de Sydney, um bom ponto de partida seria olhar para os campos de localização e menções na bio ou na timeline de celebridades teen (One Direction e Taylor Swift são, atualmente, os meus preferidos para essa categoria).
Segundo: Carregue a base de dados do Buzzmonitor com centenas de tweets do consumidor correspondente para cada timeline e divirta-se! A essa capturação de dados de tweets não-filtrados de cada pessoa chamamos de Painel de Consumidores (Consumer Panel).
O tamanho habitual de um Painel de Consumidores do Buzzmonitor é de mil a 1.200 pessoas. Carregamos de 500-1.000 tweets da timeline de cada usuário. Isto nos deixa com cerca de 500 mil a 1 milhão de itens. No entanto, o tamanho da base de dados pode vir a ser muito maior do que isso, dependendo exclusivamente do grau de profundidade e do orçamento de cada projeto. No momento em que este artigo é escrito, já fizemos experiências com projetos que chegam aos 50 milhões de itens.
Organizar o Big Data dos consumidores no Twitter
Uma vez estabelecidas as condições preliminares, é hora de passarmos ao próximo passo na extração de insights da base de consumidores. Iremos utilizar um dos nossos próprios painéis de consumidores composto por 5.000 australianos selecionados aleatoriamente e que sevirá de exemplo como procurar insights. Trata-se, principalmente, da criação de relatórios com base em termos que identificam comportamentos e ações dos consumidores. Por exemplo, você pode começar com verbos típicos como: observar, beber, comer, ter, adquirir, comprar, e ainda incluir a variação de tempos verbais. A Figura 4 demonstra isto.
No nosso primeiro gráfico capturamos tweets das timelines das 5.000 pessoas e procuramos o termo “ver”, depois os termos mais frequentes na totalidade desses tweets. Vimos que existem 195 menções a hashtag #bbau, que se refere ao Big Brother Austrália. A hashtag #theblock refere-se a outro reality show australiano e tem 69 menções.

Figura 4 – Top Termos de menções ao termo “ver” em setembro.
Estes dados podem ser ainda filtrados de modo a isolarem mais atributos, tais como sexo ou a bio. O gráfico da Figura 5 ilustra a distribuição de gênero em uma amostra de pessoas em que os termos “ver” e “jogo” foram ambos mencionados. Como a figura mostra, 8% eram homens e 25% mulheres. Os campos desconhecidos correspondem a nomes de usuários impossíveis de classificar.

Figura 5 – Distribuição por gênero.
Em seguida, vamos olhar para bebidas populares como Coca-Cola, Pepsi, cerveja, vinho e café. Criamos um relatório para cada bebida e mapeamos a evolução do volume de menções dentro da nossa base de consumidores. Os resultados abaixo referem-se a café.

Figura 6 – Menções diárias a “café”.
No quadro acima vemos uma tendência interessante: as menções ao termo café tendem a duplicar ou triplicar durante os fins de semana (sexta e sábado). Podemos claramente observar os picos de volume no gráfico precisamente nesses dias. É certo que não podemos afirmar logo que o consumo de café aumenta aos fins de semana, mas não deixa ser uma informação valiosa para qualquer pessoa que trabalhe na área de vendas de café: o fim de semana é o período ideal para promover um produto ou serviço no Twitter.
O Buzzmonitor disponibiliza um motor de geração de relatórios semelhante aos que fazem parte das ferramentas clássicas de Business Intelligence. O motor de relatórios permite ao analista gerar quantos relatórios quiser. Ao combinar termos de busca selecionados a partir de dezenas de milhares de tweets, através de buscas nos campos bio e localização, torna-se possível gerar relatórios sobre qualquer tópico que possa emergir no fluxo a partir da nossa base de consumidores. A Figura 7 mostra exemplos de relatórios relacionados à alimentação e bebidas: estamos observando menções a cerveja, café, vinho, chocolate, frango e bacon.

Figura 7 – Outros relatórios possíveis.
O ouro escondido nas bios do Twitter
O campo bio do Twitter é muitas vezes negligenciado pela maioria das ferramentas e projetos de monitoramento de redes sociais. Mas, na verdade, ele é uma excelente maneira de coletar dados demográficos.
Uma vez removidas as brincadeiras, o que sobra são verdadeiras preciosidades que nos dizem tudo sobre o consumidor, desde a profissão até o seu estado civil. Você pode usar o Buzzmonitor para filtrar palavras específicas do campo Bio, como música, vegan ou “fã de carros”, podendo ainda gerar os termos mais frequentes nesse campo, que por sua vez lhe oferecerão um ponto de partida para começar a conhecer melhor a demografia do assunto pesquisado.
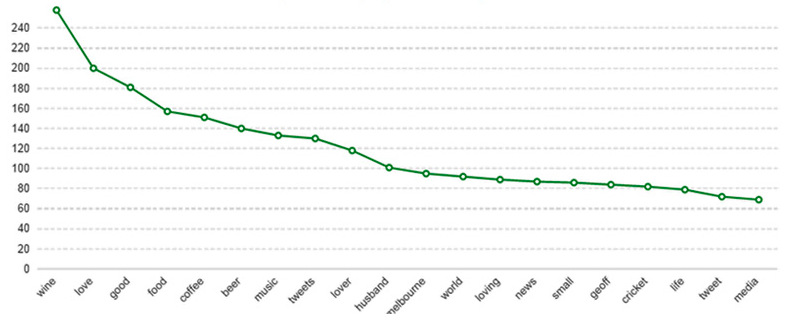
A Figura 8 mostra uma coleção de bios de pessoas que mencionaram vinho. Mesmo sem uma análise profunda já é possível fazer algumas associações: comida, café e cerveja são também mencionados em bios relacionadas a vinho. Marido (homens) e Melbourne vêm logo depois, seguidos por cricket (!). Mais uma vez é cedo demais para chegar a conclusões definitivas, mas os dados apontam para direções interessantes.

Figura 8 –Top Bios Buzzmonitor de usuários que mencionaram “vinho”.
Como posso começar o meu projeto centrado no consumidor?
Digamos que você está prestes a lançar uma nova marca de iogurte de soja. Você já sabe, através de pesquisas de mercado tradicionais, que a maioria do seu público é composto por mulheres moradoras de Melbourne e Sydney. Como você pode descobrir mais sobre este público-alvo no Twitter?
Primeiro você deverá desenhar uma busca clássica de monitoramento de redes sociais selecionando termos que presuma estarem sendo falados por esse grupo demográfico (algo semelhante a descobrir pela sua filha adolescente o que significa ser um belieber). No caso do iogurte de soja, os termos iogurte, lactose, vegan, vegetariano e “alimentação biológica” parecem ser um bom ponto de partida.
Assim que tiver dados suficientes (tipicamente entre 20.000 a 40.000 tweets), você estará pronto para filtrar uma amostra de usuários de acordo com os critérios estabelecidos: mulheres de Sydney e Melbourne. A Figura 9 mostra o painel de controle do Buzzmonitor, onde é possível configurar os filtros.

Figura 9 – Painel de controle do Buzzmonitor.
Neste momento você poderá até utilizar filtros mais fortes, tais como: pessoas da amostra que mencionaram lactose duas vezes ou pessoas que se declararam vegans no campo Bio. Cabe a você aplicar as restrições que quiser à sua lista de usuários de modo a tornar a pesquisa mais precisa ou mais genérica, dependendo dos seus objetivos. Uma vez que tenha na mão a sua bem recortada lista de consumidores, nós estaremos prontos para ajudá-lo a construir o seu primeiro Painel de Consumidores.
Dê início ao seu próprio Consumer Panel
Os consumidores querem ser ouvidos. O Buzzmonitor é a única ferramenta que automatiza o processo de escutar os consumidores de forma bi-dimensional: você não só ouvirá as conversas sobre a sua marca como ouvirá todas as conversas que o seu público-alvo tenha. Num mundo em que a atenção é escassa, saber refinar as suas mensagens através de um melhor conhecimento do seu consumidor torna-se uma grande vantagem competitiva.
Para se juntar à revolução dos consumer insights, basta se registrar gratuitamente no site www.Buzzmonitor.pt e começar a monitorar os assuntos mais prováveis de serem do interesse do seu público. Entraremos em contato para ajudá-lo a criar o seu próprio Consumer Panel assim que tenha recolhido dados suficientes. Após isso, você estará pronto para fazer tudo aquilo que lhe mostramos neste artigo!

Conclusões:
- O monitoramento tradicional das redes sociais dedica-se a capturar as conversas em torno das marcas. É uma abordagem uni-dimensional focada na marca.
- O objetivo do monitoramento centrado no consumidor é deixar de perguntar o que os consumidores estão dizendo sobre a sua marca para passar a perguntar quem está falando sobre determinada marca ou assuntos relacionados.
- A ideia fundamental é olhar para todos os tweets de um consumidor e extrair o máximo de informação relevante sobre essa pessoa. O resultado é a produção contínua de deep profiles de indivíduos através de uma busca de dados nas suas timelines no Twitter.
- O deep profile é o bloco de construção básico do Consumer Panel. O Buzzmonitor permite agregar as timelines de um público pré-selecionado do Twitter (fã de cricket, amantes de vinho, vegans de Sydney e Melbourne) e desenvolver vários relatórios de acordo com os objetivos do projeto.
- Para iniciar o seu próprio Consumer Panel vá em www.Buzzmonitor.pt, registre-se gratuitamente e comece a monitorar os termos relacionados a assuntos genéricos sobre os quais o seu público conversa. Selecione uma lista de 1.200 usuários para começar e a nossa equipa irá produzir o seu primeiro Consumer Panel.
Sobre o autor:
Jairson Vitorino, @jvitorino é CTO na E.life, a empresa responsável pelo Buzzmonitor, criada há 10 anos. É doutorado em Inteligência Artificial e atualmente reside na Alemanha.




